Mayan EDMS file converter explained
Sat, Jul 8, 2017

Document management systems first and foremost provide a place to store your documents. With Mayan, I wanted to go a step further and provide a visualization platform too. Being able to preview documents has many advantages, the primary one being that there is no need to download a document to view it, to use it. For other users, there are cost savings advantages by not having to purchase software to view their specific documents.
Mayan can provide preview images for more many document types. It uses a complex pipeline system that it often hard to understand. In this post, I’ll go over the main elements of the converter and explain why things are the way they are.
Previewing an image file is easy nowadays. Awesome Django alone lists more than 20 packages to handle images in Django. Documents are, however, a different kind of file and not all documents are easily converted to images. Having an image of a document is a good first step, but then we also need to introspect other aspects of the document, like how many pages it contains and their orientation.
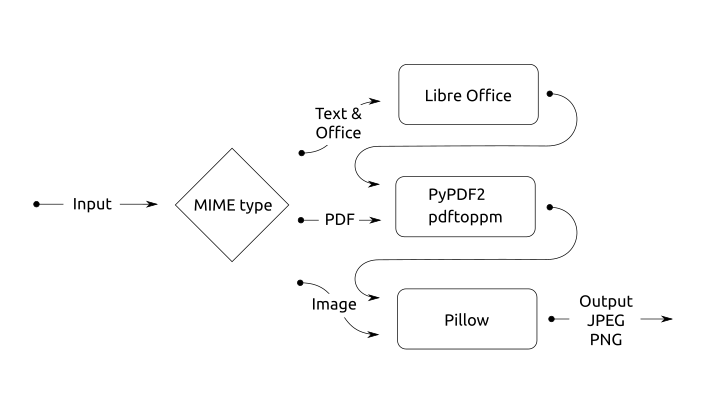
The converter in Mayan then has three main pipelines. These are the series of steps a file will take to convert it from an uploaded file to a series of images that represent it. To determine which pipeline to use, we need to know what kind of file we are handling.
Enter MIME types. MIME types (or media types) started as a way to identify which kind of attachment was included in an email to be able to encode it, decode it and consume it. Over time, the MIME types system has evolved into a standard way to describe what a file is. It is even used in HTTP. Every time your browser receives a page, the MIME type of the page is sent to let the browser know how to handle or display it. It is also used to let the browser know when it should download a file instead of displaying it. For these reasons, it made perfect sense to use MIME types to determine the conversion path a file would take. Python already provides a library for determining the MIME type of a file, but the method used by that library is not bulletproof. Why? Because it uses the filename extension. The problem is that the file extension can be readily changed and operating systems like Linux have done away with them altogether. To improve MIME type detection, Mayan uses instead the Magic library to read the file contents and introspect the MIME type based on a file’s internal markers or magic numbers. This is still not 100% accurate as some file formats don’t offer any markers so that libraries can introspect them. In these cases, the Magic library then has to rely on tricks and reversed engineered knowledge to do a best-guess. To make matters worst, some file types, like Microsoft DOCX, are just XML files compressed as a Zip file. This is why many programs detect and try to handle DOCX as compressed files. The Magic library and similar libraries then try to do introspection at several layers to increase their hit rate.
With the MIME type detected, the converter then routes the file to the proper pipeline. If a file is of a MIME type belonging to the image class, it is routed to the Pillow library. Pillow is a modern version of PIL, the Python Image Library. Pillow has knowledge on how to read, write and modify many image file formats. The first step is to determine how many “frames” or pages an image file has. This may sound strange as we are used to seeing a single image for each file we open in an image preview software. However, there are image formats that have the capability to contain multiple images, the TIFF image format is one of those. If the file is of an image type then that’s the end of that conversion pipeline and we have all that’s needed to display previews of the file.
But what if a file is not an image? Then we try to see if it is of a type that is easily converted to images. The PDF format falls in this category. PDF began as a proprietary format to create documents that could be shared among different kinds of devices. Unlike an image file which has pixels of colors to represent information, a PDF file has text commands to represent the layout of a document. This layout includes descriptions of text, embedded images, and fonts. It is a file that “describes” how to create a multi-page document. This is why PDF files need to be rendered and their output can vary from software to software. PDF eventually became an almost public standard (ISO 32000-1:2008). But like any proprietary based standards, there are still parts and extensions defined only by the standard creators for their commercial use, which causes compatibility problems. If the converter encounters a PDF file, the file is routed through the Python library PyPDF2 to determine the page count. PDFs can also be encrypted, and for some unknown reason, many programs that produce PDF files encrypt them with a blank password. If the converter encounters an error trying to introspect the page count, it will try to decrypt the PDF file using a blank password and retry the page count detection. If the page count detection succeeds the file is processed with the software pdftoppm. pdftoppm is a utility included in the suit of programs to manage PDF files called Poppler. pdftoppm renders the PDF file and saves a PPM image for each page. PPM stands for portable pixmap format and is an open image format. The PPM files corresponding to each page are then reprocessed by the converter in the first pipeline, using Pillow to convert them to the more common JPEG and PNG formats for use in the HTML front-end and other areas of Mayan.
The third pipeline of the converter is for office or text type files. Like PDFs, these need to be rendered too before they can be handled as images. These files however, are not easily rendered to images directly. For rendering, the software Libre Office is used. Libre Office is not a single program but a suit of programs to handle the typical list of office document (text documents, spreadsheets, presentations, etc). The converter uses Libre Office to render the files into an office document that is held in memory and then exports this office document into a PDF file. With the office documents exported as a PDF file, the converter then sends the PDF file to the second pipeline, which converts it into a series of PPM files which are then sent to the first pipeline, converting them into JPEGs or PNGs files.
The converter is at the heart of the visualization capabilities of Mayan and an integral part of the introspection needed for other features like OCR. Over time it continues to be expanded and improved to increase its file type handling capabilities. There are still many things in its roadmap for inclusion in future versions and more are added with each release. This is why your feedback on file formats that are not rendered correctly is very important. If you have a file that is not displaying correctly please leave a message in the forum. This way the necessary code to display it can be added to the converter or a new pipeline will be created, so you don’t need to download it every time you need to access it.








